ARM based Recommender System in Python for Trustworthiness with Emotion Recognition
Imagine a time when you’re feeling down and haunted by regrets and bad memories. Wouldn’t it be nice to have someone who understands your feelings and can help you decide who to trust? Well, what if that “someone” could be a machine?
It may sound crazy, but with machine learning models, we can make it a reality. Today, I am going to introduce you groundbreaking ARM based Recommender System in Python for trustworthiness with emotion recognition. By using Python and the power of machine learning models, this system will be able to understand the person’s emotions and on the basis of emotions we will decide if the person is Trustworthy or not. Join me in uncovering the potential of sentiment analysis and trust assessment and discover the exciting horizons that await us. 🤠

In this article, I am going to walk you through my case study ARM based Recommender System in Python for Trustworthiness with Emotion Recognition step by step, along with the intuitions I discovered. To make it easy for you to track across my blog, the contents are as follows:
1. Overview
2. Introduction
3. Business use case
4. Mapping to ML problem
5. Understanding the Data
6. Model Architecture
7. Results
8. Conclusion
9. Future Work
10. Acknowledgement
11. References
So, excited? Let’s begin!! 😜
1. Overview
Trustworthiness is the essence of a person or a thing which inspires reliability.
As a human, trust is one of the most important things we care about. In recent years, the growing popularity of social media has resulted in making it a crucial platform for expressing emotions. People pour their heart out on social media for their opinions, secret feelings, overjoyed moments, thoughts that worry them or ideas which blows their mind off and the communication with each other through the text messages. Social media status, textual messages have become the most influential part of their life. This has resulted in the creation of a tremendous amount of user-generated content. But, there is no easy way to distinguish whether the content is trustworthy. A casual viewer might not be able to differentiate between trustworthy and untrustworthy content.
This study addresses the challenge of determining the trustworthiness of shared content on social media. It focuses on Emotion Recognition and Association Rules to identify human emotions and their connections. Data from social media (Twitter), newspaper headlines, and articles are used. The proposed approach involves Ensemble Classifier, Random Forest Regressor, and Association Rule Mining. It includes identifying frequent emotions, specifying relevant categories, and using feature embedding to recognize trustworthiness on social media.

2 . Introduction
Emotion was defined in Oxford Dictionary as
“A strong feeling deriving from one’s circumstances, mood, or relationships with others”.
Since human emotion is the great supporter to human behavior, it’s become crucial to seek out a course of action to acknowledge emotions automatically by machines.
To refresh Emotion recognition, straight from Wikipedia:
“Emotion recognition is the process of identifying human emotion. People vary widely in their accuracy at recognizing the emotions of others. Use of technology to help people with emotion recognition is a relatively nascent research area.” — Wikipedia 2021.
For my analysis, I have used Ekman’s basic human emotions: anger, disgust, surprise, joy, sadness, guilt and shame. These emotions are characterized as universal, as they’re expressed within the same way across different cultures and eras. Ekman’s emotion model has been employed in several research studies and in various systems that are wont to recognize emotion from textual data and facial expressions.
3 . Business Use Case
ARM based Recommender System in Python for Trustworthiness with Emotion Recognition uses Machine Learning Models to analyze text and determine whether the writer’s perception is trustworthy or not. The Emotion Recognition has become a key tool for creating sense of the multitudes of opinions expressed daily on review sites, forums, blogs, and social media. As you’ll already guess from what we’ve got discussed, having the ability to spot emotions is extremely useful. Let’s see:
3.1 Social Media Analysis
Online reputation is one amongst the foremost precious assets for brands. a foul twitter review may be costly to a corporation if it’s not handled effectively and swiftly. With the assistance of ARM based Recommender System in python for Trustworthiness with Emotion Recognition, you’ll be able to define alerts to avoid reputational crisis or define priorities for action so as to supply insights and improve user experience if the resultant label is untrustworthy.
4. Mapping to ML problem
The core of this case study is multiclass classification of Ekman’s Emotions . From the given twit, we are going to predict the person is trustworthy or not.
4.1 Performance Metrics for ML Algorithms
4.1.1. Classification Accuracy
Classification Accuracy is the ratio of number of correct predictions to the whole number of input samples.

where,
True Positives (TP) − it's the case when both actual class & predicted class of knowledge point is 1.
True Negatives (TN) − it's the case when both actual class & predicted class of knowledge point is 0.
False Positives (FP) − it's the case when actual class of information point is 0 & predicted class of information point is 1.
False Negatives (FN) − it's the case when actual class of knowledge point is 1 & predicted class of knowledge point is 0.
4.1.2. Classification Report
This report consists of the Precision, Recall, F1 and Support. they’re explained as follows –
a. Precision
Precision, utilized in document retrievals, could also be defined because the number of correct documents returned by our ML model. we will easily calculate it by confusion matrix with the assistance of following formula .

b. Recall
Recall could also be defined because the number of positives returned by our ML model. we are able to easily calculate it by confusion matrix with the assistance of following formula -

c. F1 Score
This score will give us the mean value of precision and recall. Mathematically, F1 score is that the weighted average of the precision and recall. the simplest value of F1 would be 1 and worst would be 0. we are able to calculate F1 score with the assistance of following formula

F1 score has equal relative contribution of precision and recall. We can use classification_report function of sklearn.metrics to induce the classification report of our classification model.
4.1.3. Root Mean Square Deviation
The Root Mean Square is defined as the value of square root of mean of square of N numbers.
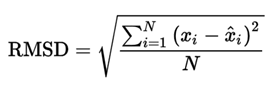
4.2. Metrics for Association Rule Mining
In order to find the interesting patterns or set of rules from the frequent data, metrics on various measures of significance and interest are used. The absolute best known metrics are support and confidence.
4.2.1.Support
“Support is an indication of how frequently the itemset appears in the dataset.”,(Wikipedia). This is often a very important metric to shows how frequent an item is appeared in itemset in all transaction. Consider X = {anger, disgust, fear, happiness, sadness, surprise, shame} is the set of emotions called as items and Y = {t1,t2,t3,…..tn } is the set of transactions called as dataset. The dataset has a unique transaction ID and a subset of emotions. Then support can be calculated as ,

4.2.2.Confidence
“Confidence is an indication of how often the rule has been found to be true.”, The confidence of rule X→Y can be defined as the probability of viewing of the appearance of ‘consequents’ itemset ‘Y’ in the cart given that the ‘antecedents’ itemset ‘X’ is already in the cart, ‘p(Y | X)’. Then confidence can be calculated as ,

4.3 Constraints:
4.3.1. Small size Dataset
In Emotion Recognition the ISEAR dataset is tiny so model wasn’t trained well. Hence the result was low accuracy. It last turns into the poor Association Rules. Hence it had been creating an issue in feature embedding. So, it absolutely was very difficult to require decisions on these rules.
4.3.2.Shortcomings of Python
a. Performance and Speed
Many studies have proved that Python is slower than other modern programming languages like Java and C++. therefore the developers should frequently explore ways to reinforce the Python application’s speed.
b. Incompatibility of Two Versions
Beginners often find it pick and learn the correct version of Python. Officially, Python 2.x is described as legacy, whereas Python 3.x is described as current and futuristic. But both versions of the artificial language are updated on an everyday basis. Also, an outsized percentage of programmers still prefer Python 2 to Python 3. There also are variety of popular frameworks and libraries that support only Python 2.
c. Depends on Third-Party Frameworks and Libraries
Python lacks variety of features provided by other modern programming languages. Therefore the programmers must use variety of third-party frameworks and tools to make web applications and mobile apps in Python.
Looking for a way to support my learning journey? Buy me a book and be a part of my intellectual growth! 📚🌱
5. Understanding the Data
5.1. ISEAR data
The ISEAR stands for “International Survey on Emotion Antecedents and Reactions” database that's constructed by Swiss National Centre of Competence in Research and lead by Wallbott and Scherer. It mainly consists of seven labels: joy, sadness, fear, guilt, anger, disgust, and shame. This dataset carries a whole of 7k sentences categorized with emotions Field.
5.2. News Headlines Data
This dataset contains around 200k news headlines from the year 2012 to 2018 obtained from HuffPost. This dataset might be accustomed produce some interesting linguistic insights about the type of language employed in different news articles or to easily identify tags for untracked news articles. (9000+ downloads on Kaggle). Here, is an example how one headline is predicted.

5.3. Articles Data
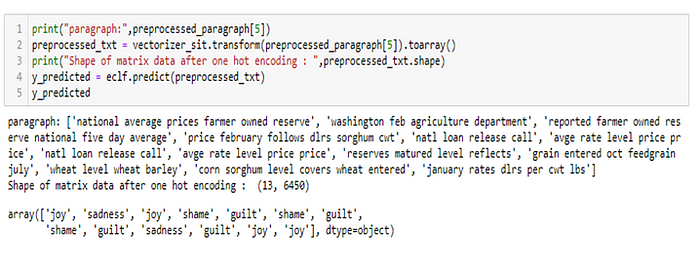
The documents within the Reuters collection appeared on the Reuters newswire in 1987. The Reuters collection consists of 22 data files, an SGML DTD file describing the data file format. The documents were assembled and indexed with categories by personnel from Reuters Ltd. and Carnegie Group, Inc. in 1987. Lets see how one paragraph from article’s emotion is predicted.
6. Model Architecture
The Proposed Framework is processed in four phases. First one is Data Augmentation phase, second is Feature extraction and Ensemble Classifier Training phase, third is Association Rule Mining phase and fourth one is Trustworthiness Evaluation phase. The output of all the phases is different from each other. In the architecture below we can see, the first output is the augmented ISEAR data , second is predicted emotions, third is association rules and fourth is trustworthiness. We are going to see these phases in detail.

6.1.Data Augmentation
The first and most important phase of the implementation. For most of the machine learning task, data augmentation has been used while training machine learning models. The more diverse examples fed to the model during training, the better the model predicts when new examples appeared and over fitting is reduced.
This is well known that building a good machine learning model requires a large amount of data. But original ISEAR dataset is not large. Then it became too challenging to make model perform well on small amount of data. Hence the Data Augmentation appeared as the new way to improve performance and create robustness. There are three methods are used in DA :
1. Word2Vec
2. WordNet
3. Round-trip Translation
As we can see in below diagram. We can use it in combine or one by one as per our choice. The best way to know these in detail is here.

6.2 . Feature extraction and Ensemble Classifier Training Phase
The Augmented ISEAR dataset, after the preprocessing and feature extraction trained with the ensemble classifier model to find the predicted output.
6.2.1. Preprocessing
To make data ready for analysis is such a important step. The preprocessing includes: Removing numbers, removing punctuation, making all text lowercase, removing stopwords. Removing repetition word like ‘headline’ from headline data.
6.2.2. Feature Extraction
Feature Extraction or Vectorization could be a way where the textual data must be parsed to remove certain words(tokenization) then be encoded as integers or floats for use as input to machine learning algorithms. Scikit-learn’s CountVectorizer is employed for this process. This gives us highly flexible features representation for text. These features are the key for my project.
6.2.3.Ensemble classifiers
Ensemble classifiers are the machine learning algorithms , which fits collectively to get better predictive overall performance than any single algorithm obtained. The aim using the ensemble classifiers was certainly to improve performance as ensemble classifiers use extensively in text classification and ensembles is used to take the learners advantages and to reduce its drawbacks.
a. XGBoost Algorithm :
If you would like speed and accuracy, XGBoost algorithm is the solution. It’s a robust machine learning algorithm, is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. The XGBoost model for classification is termed as XGBClassifier. We can create and fit it to our training dataset. You’ll read it in details , here.
b. Random Forest Classifier
Random Forest is an ensemble method for classification and regression. Just like the name, random Forest contains number of individual decision trees gives individual class prediction output and then the class which has most votes becomes the Random Forest Classifier model’s prediction. See in detail, here.
c. Support Vector Classifier
SVM works relatively well when there’s transparent margin of separation between classes. SVC is employed for multiclass classification. Number of records, embedding dimensionality can speed up SVC training. Use SVC(probability=True) if you need the probabilities.In detail here.


6.3.Association Rule Mining Phase
Shortly descripted, above trained ensemble classifier applied on Preprocessed News Headlines and News Articles to create an inventory of emotions. In the above diagram we are able to see, the generated Transaction ID and ItemList table where Transaction ID have unique column values and ItemList encompass emotions per Transaction ID. The predicted Emotions can be one, two or set of multiple emotions. From that Association Rules are generated. Now by using the feedback of Association Rules I’ve got done Feature Embedding here and Transform train vector into new one and trained new vector with Random Forest Regressor.
Hey, don’t get headache ok! …. we will see it step by step.
6.3.1. Association Rule Mining
Looking Back , When I was studying Data Mining in my masters , I was eager to introduced so many interesting concept but one concept I heartily enjoyed is Association Rule Mining because first it’s so based on our everyday market-basket and suggests me an items based on what I have in my cart, second how this is widely used to take business decisions in market. I did my mega project in ARM, still not over with it. Hehehe!
What Wikipedia wants to say !
“Association rule learning is a rule based machine learning method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using some measures of interestingness. “–Wikipedia , 2021
Consider following example :

An association rule is an assumption of the form X = {eggs , bread} , Y= {butter} of {eggs , bread}→{butter}, where {eggs , bread}⊆I , {butter} ⊆I and {eggs , bread}∩{butter} = 0. The rule {eggs , bread}→{butter} clasps the transaction set D with the aid of support s, where s is assumed as the percentage of transaction in D that consist of X U Y. This is assumed to be the probability, P(X U Y). The rule X→Y has confidence c in the transaction D, where c is known as the percent of transaction in D consisting X that also consist Y. This is assumed to be the conditional probability, p (Y|X). Hence,

In above example , X is antecedent and Y is consequent. Both antecedent and consequent can consist of single or multiple items.
Very cool, right!
6.3.2. Apriori Algorithm
Apriori Algorithm is developed by R. Agrawal and R. Srikant to find the frequent itemsets in a dataset. The name of Apriori is based on the fact that the algorithm uses a prior knowledge of frequent itemset properties. The purpose of the Apriori Algorithm is to find associations between different sets of Data. Each set of data has a number of items and is called a transaction. The first pass of this algorithm simply counts item occurrences to determines the frequent itemsets.

From the generated association rules, the sample bar graph of consequent emotions are as follows:

6.3.3. Semantic similarity
Now days you may find such a lot of applications where semantic similarity plays an very important role. The most essence of this project is to make use of WordNet to seek out the similarity between the Features and applying support values to the most similar features . WordNet consists of Synsets which are organized in a very hypernym tree. This tree gives the reasoning about the similarity between the synsets. If the 2 synsets are closer means they are more similar. One of the core metrics used to calculate similarity is that the shortest path distance between the two Synsets and their common hypernym. In detail , here. Here is an example:

6.3.4. Feature Embedding (wordToVector)
Feature Embedding is defined as the transformation of vector from low dimensional space into high dimensional vector or vice-versa. The idea was to replace the values of the X_train and X_test data from augmented ISEAR dataset with support and y_train and y_test values with confidence values from association rules.

6.3.5. Random Forest Regressor
Random Forest is defined as an ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap and Aggregation, commonly known as bagging. The final output would mean of all the outputs. The basic idea behind this was to combine multiple decision trees in determining the final output that would be label ‘trustworthy’ or ‘not trustworthy’ from the means of all output.
6.4. Trustworthiness Evaluation Phase
This is the fourth and final phase of my case study. Thinking about twitter data, it is possible to say that there is a lot of it, considering that millions of social media posts are being created every second. I have use here 4 labels data i.e. sadness, joy , anger and fear. After cleaning the data, with the help of feature dictionary feature embedding matrix is created. Then trained Random Forest Regressor is applied and found the desired result.
7. Results
The aim of using ensemble classifiers was to improve performance over the ISEAR dataset and gives the best prediction results. It certainly has achieved than any other machine learning classification models. We can see below training and test accuracies along with their classification report. The correct accuracy is like hitting the bull’s eye and helps for the future decisions.

As I have said before, all the phases have different result. Where ensembles gives above results the Association rule mining gives the rules with the relationship of emotions and different support and confidence values for every emotions and the group of emotions. Like below:

These support and confidence values I have used for Feature Embedding. Then here comes the role of RF Regressor which gives the lowest RMS values hence showed it is the best model to predict the trustworthiness.

On the basis of predictions , following result has been obtained that would be from one twit the model will show the person who wrote that twit is trustworthy or not.


8. Conclusion
Aaah !!! We reached to the conclusion. I was enjoying sharing this idea with you about ML and ARM. It was very challenging thing to make association rules work on emotions. But it turns out to be the best to take some decisions after emotion recognition. Specially, when I shortlisted the rules and use them to recommend the trustworthiness.
To the best of my knowledge , my results are the first generalization bounds for the problem of Trustworthiness from Emotion Recognition with ARM. Now next time if u wonder that who is able to find trustworthiness from twitter text the machine will definitely reply “ I do !!!” . I tried to make everything simple, coding as well as blog, I hope you enjoyed this too. Association Rule Mining and Analysis is a very wide topic to cover in one blog but I hope that this will encourage you to explore more and expand your imaginations. Start with the references links. It can drive you crazy but I guess you will enjoy that too. Hehe!!😂😂
9. Future Work
I think the most important bit for ARM based Recommender System for Trustworthiness with Emotion Recognition in the future has to do with improving the accuracy of the algorithms. I tried my best to found the relationship between sentiments with the help of Association Rules but just felt like scratching the surface there. I suppose there will be a work on rating to show the person is how much trustworthy. The tools and methods for this typology of challenges already exist and can be found in the shape of machine learning methods.
10. Acknowledgment
I feel so grateful to Brahma Reddy Sir and whole AAIC team for their invaluable help because I had faced many challenges while completion of this case study and still finished it with better results. And Due to their support, my blogging journey has also begun in January of this year, I applaud.👏 Thank you for those who took time for reading this blog ARM based Recommender System in Python for Trustworthiness with Emotion Recognition. I truly appreciate your insights and personal connection.
I would love to hear your thoughts and opinions! Feel free to leave a comment.
Don’t miss out on the fun — subscribe here and get my articles delivered straight to your inbox!
sample data links are in references .
You can find the code in python on Github.
You can visit the ML Deployed app here.
You can visit YouTube also for demo video here.
You can reach me on LinkedIn.
Stay tuned!!💃
11. References
[1] https://www.appliedaicourse.com/
[2]https://www.sciencedirect.com/science/article/abs/pii/S0952197616000166
[3]https://www.sciencedirect.com/science/article/abs/pii/S1877750318311037
[4] https://ieeexplore.ieee.org/document/7342691
[5]https://arxiv.org/pdf/1907.03752
[6] https://medium.com/towards-artificial-intelligence/step-by-step-guide-in-creating-your-own-emotion-recognition-system-b8aba98134c8
[7] https://en.wikipedia.org/wiki/Random_forest
[8] https://en.wikipedia.org/wiki/Support_vector_machine
[9] https://www.geeksforgeeks.org/association-rule/
[10] News Paper : https://www.kaggle.com/rmisra/news-category-dataset
[11] Articles : https://archive.ics.uci.edu/ml/datasets/reuters-21578+text+categorization+collection
[12] Twitter data : http://saifmohammad.com/WebPages/EmotionIntensity-SharedTask.html
[13] ISEAR data : https://www.kaggle.com/shrivastava/isears-dataset

{kind=link}